
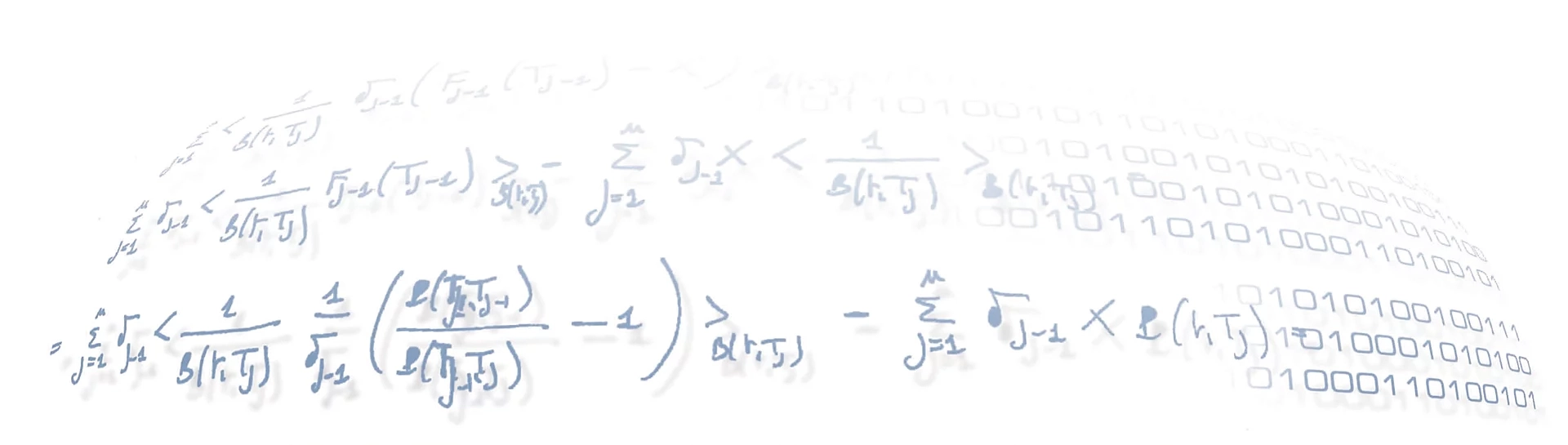

29 January 2021 RecSys for MAD: backtesting resultsRecSys AD |
6.1 Non-Supervised Learning Backtesting
Although, as said, we are not in a supervised learning setup, we wanted to try to set up some sort of a backtesting facility for our empirical study.
Specifically, for the training of the RecSys we have removed the last five working days from the three months of available data, leaving them aside for the subsequent testing phase.
The main purpose is not, indeed, to be able to accurately quantify the reliability of the RecSys as an anomaly detector — without any reference anomaly to compare its alarms with. Its aim is instead to provide a kind of ‘investigation lab’ that would allow for qualitative analysis such as gauging the number of alerts raised or inspecting directly with a human-eye the transactions reported.
In what follows we will focus on the results of three specific instances of RecSys among those described so far. For convenience, we will use the notation RecSys(user,item) to refer to each of them, depending on what was used as user and as item dimensions. Namely we will use:
- RecSys(U,I) to denote the RecSys which uses
- the subject as the user dimension
- the security ISIN as the item dimension
- RecSys(U,V) to denote the RecSys which uses
- the subject as the user dimension
- the countervalue as the item dimension
- RecSys(U,I+V) to denote the RecSys which uses
- the subject as the user dimension
- a join of the ISIN and a per-subject volume-level as the item dimension
6.2 Resulting anomalies
| Top ten anomalies for RecSys(U,V) | ||||||
| DATE | SUBJECT | vbinx | vbin | # | n-score | z-score |
|---|---|---|---|---|---|---|
| 2019-11-12 | 41932450 | 19 | ~3.2e+06 | 1 | 0.909352 | 2.249750 |
| 2019-11-14 | 41932450 | 19 | ~3.2e+06 | 1 | 0.909352 | 2.249750 |
| 2019-11-15 | 49751457 | 19 | ~3.2e+06 | 1 | 0.891372 | 2.124371 |
| 2019-11-14 | 49751457 | 19 | ~3.2e+06 | 1 | 0.891372 | 2.124371 |
| 2019-11-15 | 44159571 | 19 | ~3.2e+06 | 1 | 0.890290 | 2.112326 |
| 2019-11-11 | 1043496 | 19 | ~3.2e+06 | 1 | 0.849349 | 1.784060 |
| 2019-11-15 | 24093493 | 18 | ~1e+06 | 1 | 0.847803 | 1.760141 |
| 2019-11-12 | 1043453 | 18 | ~1e+06 | 1 | 0.832035 | 1.681002 |
| 2019-11-13 | 1043453 | 18 | ~1e+06 | 1 | 0.832035 | 1.681002 |
| 2019-11-15 | 36211507 | 18 | ~1e+06 | 2 | 0.798511 | 1.517740 |
The table here shows the first ten records — in descending order according to the anomaly score — within the 5 days of the ‘backtesting’ dataset as returned by RecSys(U,V).
To clean up this shortlist from the low-volume side anomalies, which are supposed not to be relevant in a MAD perspective, a preliminary filter has been applied to remove all records with a volume bin below 1.0e+00.
Since a RecSys returns an anomaly score based just on the pair (user, item), it is quite possible that more than a deal appear in the testing dataset that belong to the same pair: for RecSys(U,V) it corresponds to the case in which the same subject has performed more than one transaction, perhaps with different ISINs, in which the individual volumes fell within the same bin.
This is the meaning of the column ‘#’ in these tables, in which the count of the transactions that correspond to that particular anomaly is reported.
We kept these counting separated for each single day of the testing dataset, as if our anomaly detection tool had run on a daily basis, reporting the anomalies of each single day.
This is why, for example, the first two lines, apparently identical, appear distinct — the transactions occurred for the same subject with the same volume bin, but on two different days — while the last one was merged with a count of #2 — the transactions occur on the same day.
The plain way to read this table is that the most anomalous record corresponds to a deal made by subject 41932450 with a countervalue remarkably greater than 1 million but remarkably lower than 10 million as well. This is because the bin labelled as ~3.2e+06 is just the one between (in a log scale) the two bins centered in the ‘round numbers’ 1 million and 10 million, respectively.
Such deal was made twice, within the five days of our testbed, the first on Nov. 12th and the second on Nov. 14th.
The n-score is about 90% near to top but the really meaningful number is the z-score, which says that such anomaly is just over ‘two sigma’ away from the average score: so not really much an anomaly indeed.
The plain way to interpret this result is that a deal with a countervalue as large as that one is quite unusual for that subject or for similar subjects — similar, let’s stress this once again, in the specific meaning tha the RecSys itself build up, namely, for RecSys(U,V), that usually execute orders with similar countervalues.
| Top ten anomalies for RecSys(U,I) | ||||||
| DATE | SUBJECT | ISIN | # | n-score | z-score | |
|---|---|---|---|---|---|---|
| 2019-11-15 | 1000456 | JP3942800008 | 1 | 0.972784 | 3.851117 | |
| 2019-11-11 | 1000456 | JP3942800008 | 1 | 0.972784 | 3.851117 | |
| 2019-11-13 | 1043896 | CH0002187810 | 2 | 0.944832 | 3.374233 | |
| 2019-11-12 | 1043896 | US92823T1088 | 5 | 0.943670 | 3.363270 | |
| 2019-11-15 | 1043896 | IT0005388449 | 1 | 0.939825 | 3.314311 | |
| 2019-11-13 | 1043896 | IT0005388449 | 1 | 0.939825 | 3.314311 | |
| 2019-11-12 | 1043896 | IT0005388449 | 2 | 0.939825 | 3.314311 | |
| 2019-11-14 | 1009036 | GB0009039941 | 2 | 0.939060 | 3.307272 | |
| 2019-11-11 | 1009036 | US6443931000 | 1 | 0.938117 | 3.270927 | |
| 2019-11-15 | 1043896 | SG1P32918333 | 1 | 0.936573 | 3.220750 | |
| Top ten anomalies for RecSys(U,I+V) | ||||||
| DATE | SUBJECT | ISIN@vol-level | # | n-score | z-score | |
|---|---|---|---|---|---|---|
| 2019-11-15 | 1026339 | FR0000120354 H | 1 | 0.971891 | 3.435978 | |
| 2019-11-15 | 1039910 | IT0005388449 H | 2 | 0.965881 | 3.344399 | |
| 2019-11-12 | 1039910 | IT0001352217 H | 2 | 0.964955 | 3.330588 | |
| 2019-11-15 | 1039910 | BE0003839561 M | 1 | 0.963047 | 3.264385 | |
| 2019-11-11 | 1028965 | IT0005388449 H | 1 | 0.962350 | 3.255562 | |
| 2019-11-15 | 1028965 | IT0005388449 H | 3 | 0.962350 | 3.255562 | |
| 2019-11-14 | 1028965 | IT0005388449 H | 1 | 0.962350 | 3.255562 | |
| 2019-11-13 | 1043896 | CA00851F1062 M | 1 | 0.958739 | 3.182827 | |
| 2019-11-15 | 1021212 | US8485741099 M | 1 | 0.958391 | 3.170235 | |
| 2019-11-14 | 1007594 | US2537483057 M | 1 | 0.952928 | 3.064075 | |
The next tables show the corresponding results for RecSys(U,I) and RecSys(U,I+V).
Again, to clean up the latter shortlist from the low-volume side anomalies, which are supposed not to be relevant in a MAD perspective, a preliminary filter has been applied to remove all records with the Low L subject volume-level in the item column.
En passant, compare the scores of the second row of the latter with the first row of the former: the differences are small, but in any case it is just one of those situations in which the values of the n-score and z-score are orded-reversed, highlighting the role of a universal reference of the latter.
As you can see, in both cases their topmost rows have higher values than those of RecSys(U,V). In particular, the higher values of the z-score tell us that this is not simply the effect of a different score-rescaling, but they are really more unusual transactions compared to the overall behavior of the dataset. This makes sense, since the distribution of countervalues is not rigid and compartmentalized, so even extreme countervalue for a certain subject will probably have corresponding cases, or at least quite close, in the training dataset.
In fact, as a self-consistency check, one can inspect the training dataset looking for items similar to the one reported as the most anomalous one in the test dataset.
6.3 Anomalies inspection
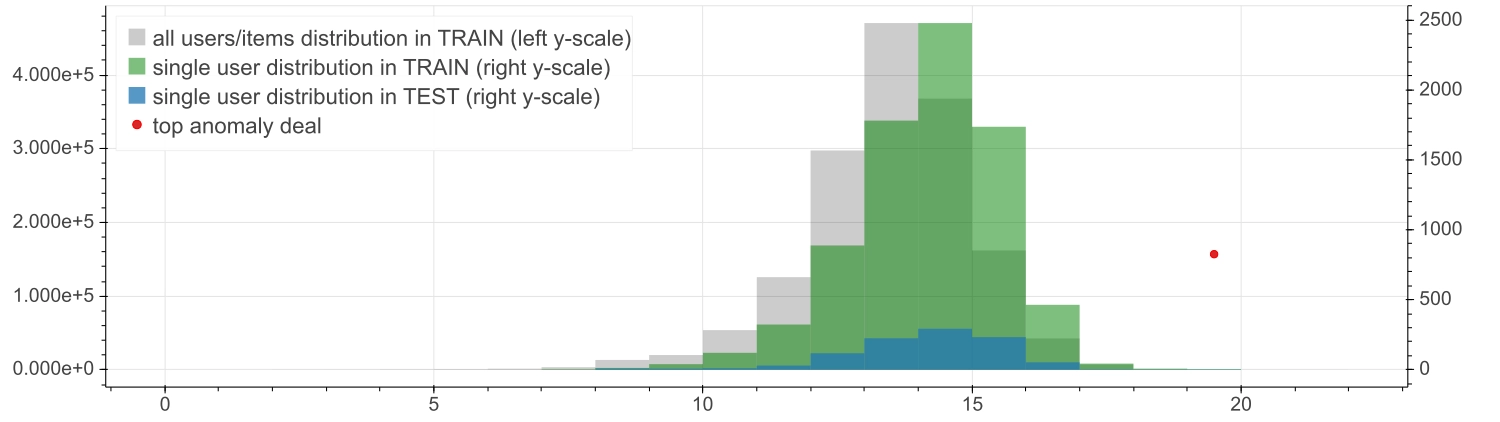
To this purpose, the figure here try to compare the empirical distributions of the countervalues for the involved user.
The gray histogram in the background shows the overall distribution of the countervalues in the training dataset against the left y-axis. The overlying green histogram shows the countervalue distribution, again in the training dataset, but just for the subject concerned, against the right y-axis to allow a comparison, given the different count scales. The same single-user distribution, but for the test dataset, is superimposed in blue.
This plot confirms that a deal with such a countervalue represents quite an uncommon case for the user in question, although not so anomalous. As a quantitative summary of the above histograms, a few numbers are reported in the following tables that read as follows.
| Inspection of the most anomalous record for RecSys(U,V) | ||||||
| NUMBER OF DEALS |
WHOLE DATASET |
USER 41932450 |
vbin ~3.2e+06 |
(41932450 ∧ ~3.2e+06) |
||
|---|---|---|---|---|---|---|
| TRAIN | 1'567'776 | 7'903 | 108 | 5 | ||
| TEST | 158'524 | 987 | 10 | 2 | ||
Among the grand total of 1’567’776 deals of the training dataset, 108 of them fall into the 19th bin (~3.2e+06) regardless of the subject, and 7’903 of them belong to the subject 41932450, including all bins; such numbers overlap in 5 deals that belong to the involved pair (41932450, ~3.2e+06).
Correspondingly, in the test dataset among the grand total of 158’524 deals, 10 of them fall into the 19th bin (~3.2e+06) regardless of the subject, and 987 of them belong to the subject 41932450, including all bins; such numbers overlap in precisely the 2 deals belonging to the involved pair (41932450, ~3.2e+06) that are reported as anomalous.
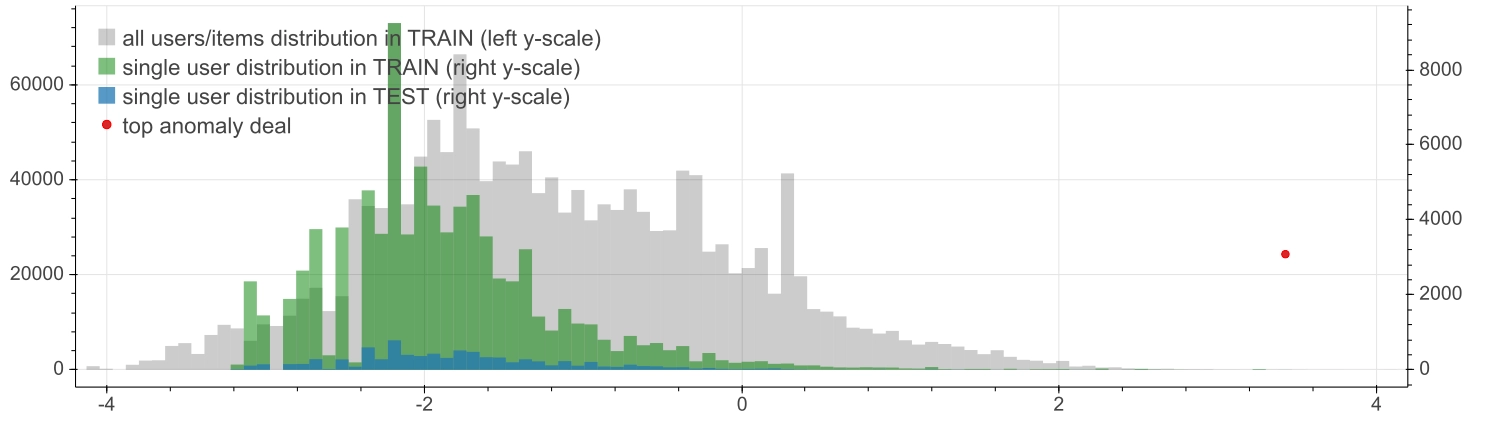
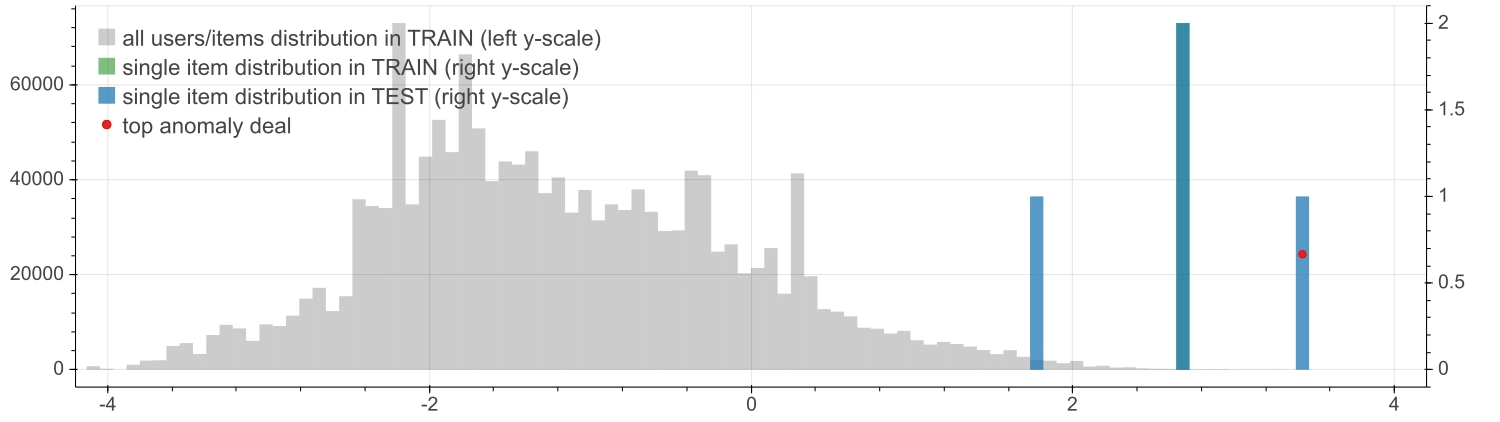
As a further investigation aimed at understanding these results, the next figures show the distributions of the z-scores focusing on the user (upper plot) and the item (lower plot) of the most anomalous record in testbed.
| z-score distributions of the most anomalous record for RecSys(U,V) | ||
 |
||
 |
||
Compared to the overall distribution in the training dataset (background gray histograms in both upper and lower plot, against the left side y-axis), the z-score of user 41932450 (upper plot, right y-axis) is concentrated in the positive region both in the training dataset (green) and in testbed (blue).
Conversely, the z-score of the volume bin ~3.2e+06 (lower plot) is biased towards the anomalous negative region, both in the training dataset (green) and in testbed (blue). This makes sense since it corresponds to the third largest bin in our dataset, so probably for many users it represents a quite uncommon countervalue.
An inspection like that of the countervalues distribution figure is not possible for the other two RecSys, since their item dimensions have no inherent quantitative meaning. However one can still take a look at the z-score distributions, focusing on the user and the item of the most anomalous record in testbed for RecSys(U,I) and RecSys(U,I+V).
| z-score distributions of the most anomalous record for RecSys(U,I) | ||
 |
||
 |
||
| Inspection of the most anomalous record for RecSys(U,I) | ||||||
| NUMBER OF DEALS |
WHOLE DATASET |
USER 1000456 |
ISIN JP3942800008 |
(1000456 ∧ JP3942800008) |
||
|---|---|---|---|---|---|---|
| TRAIN | 1'567'776 | 4'136 | 2 | 0 | ||
| TEST | 158'172 | 403 | 3 | 2 | ||
| z-score distributions of the most anomalous record for RecSys(U,I+V) | ||
 |
||
 |
||
| Inspection of the most anomalous record for RecSys(U,I+V) | ||||||
| NUMBER OF DEALS |
WHOLE DATASET |
USER 1026339 |
ISIN@vol-level FR0000120354 H |
(1026339 ∧ FR0000120354 H) |
||
|---|---|---|---|---|---|---|
| TRAIN | 1'567'776 | 86'050 | 2 | 0 | ||
| TEST | 157'562 | 8'329 | 4 | 1 | ||
This is shown in the plots above and their quantitative summary is provided by the correspondingly two tables.